
Technology
Attribyte's technology makes it easy to build applications that search, select, and analyze posts, tweets and articles aggregated from publishing platforms, feeds, websites, blogs and social media. Their content is crawled, stored and analyzed to build complex views from queries that combine full-text search with authors, hosts, images, tags, links and other metadata. Developers integrate with Attribyte using either a web-friendly JSON API or an efficient binary protocol for mobile and embedded applications. Applications receive dedicated resources for indexing, storage and API support, while content acquisition and shared state is managed by a “core” service.
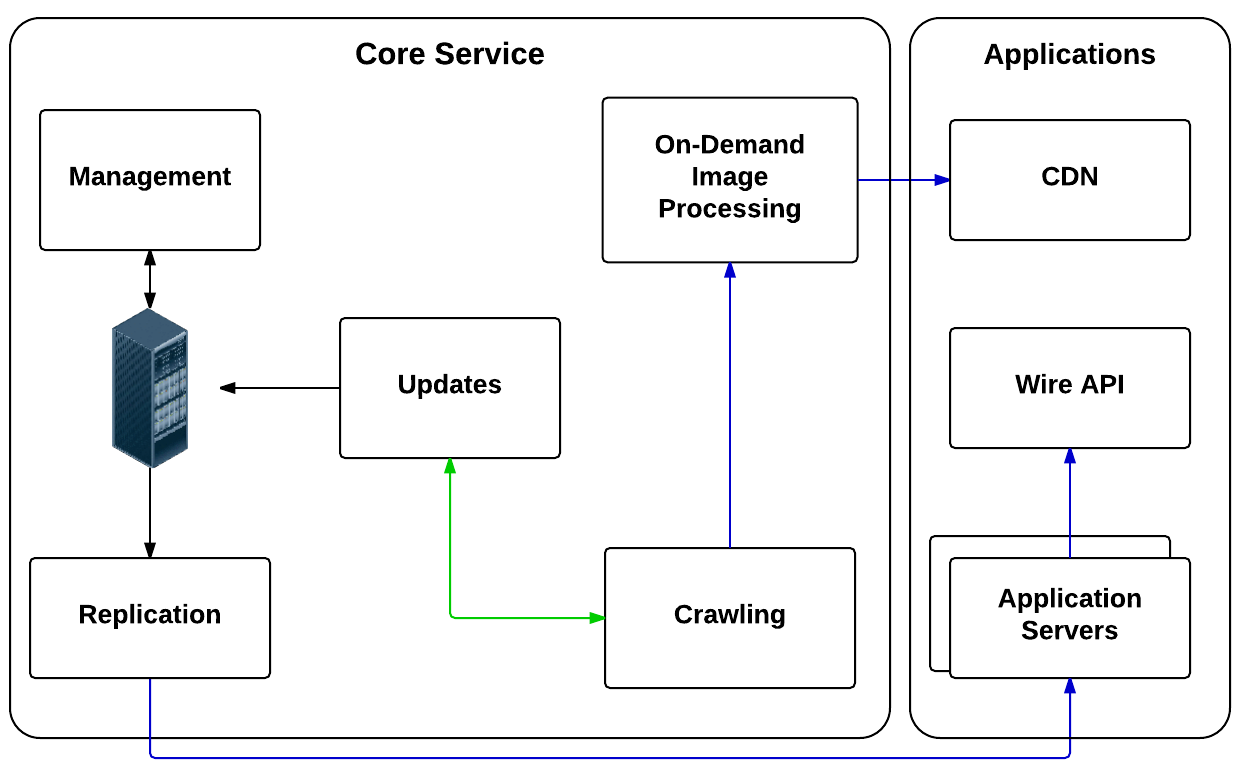
The core service continuously crawls feeds, pages, timelines and APIs to add articles, collect link relationships and extract images. On-demand image processing provides thumbnails and transformations to clients through a CDN. Application servers tie into the core service with either an efficient binary replication protocol or a publish-subscribe service. Both use authenticated HTTP for transport with mandatory TLS to ensure privacy and security, allowing nodes to be distributed to multiple cloud regions, or datacenters, without special network considerations.
Hosted applications are deployed to their own servers to allow customized index construction, private data, performance tuning and high availability. Nodes share no state; each locally manages its own index and storage. This provides the ability to scale at the expense of brief inconsistency. In the event of a core service failure, application nodes remain available in a degraded “read-only” mode, which, for most applications, is the desired behavior. This design enables a wide range of applications to be deployed on Attribyte’s platform, while ensuring their API-availability, scalability and performance are independent.